コードなしでWebページからデータを抽出する5つの方法
2026年4月28日
Webページに商品価格の一覧、企業ディレクトリ、求人リストが表示されている。そのデータをスプレッドシートに入れたい。従来の方法はPythonでウェブスクレイピングですが、コードが書ける前提です。プログラミング不要の実用的なアプローチが5つあり、それぞれ労力・正確さ・スケールのトレードオフが異なります。
1. コピー&ペーストでスプレッドシートに
最もシンプルな方法。ページ上のデータを選択、コピーして、Google SheetsやExcelに貼り付けます。最新のスプレッドシートはHTMLコンテンツのテーブル構造を意外なほどきれいに保持します。
うまくいくとき:
- 小規模な一回限りの抽出(50行以下)
- データがきれいなHTMLテーブルで表示されている
- セットアップゼロで今すぐデータが必要
うまくいかないとき:
- データが複数ページにまたがる(ページネーション)
- ページが動的読み込みを使用(スクロールでコンテンツ表示)
- テーブル構造が貼り付け時に崩れる
労力: ゼロ。 スケール: 非常に小。 正確さ: ページ構造に依存。
2. Google Sheetsの IMPORTHTML / IMPORTXML
Google Sheetsには、Webページからデータを直接取り込む組み込み関数があります:
=IMPORTHTML("URL", "table", 1)— ページの最初のHTMLテーブルを取り込む=IMPORTXML("URL", "//xpath")— XPath式に一致するデータを取り込む
うまくいくとき:
- データが標準的な HTML
<table>要素にある - スプレッドシートを自動更新したい
- 安定したURLの単一ページからデータが必要
うまくいかないとき:
- ページにログインやJavaScriptレンダリングが必要
- データが
<table>タグにない(divベースのレイアウト、カードグリッド) - Googleのレート制限で頻繁な更新がブロックされる
労力: 低(1つの数式)。 スケール: 低〜中。 正確さ: 適切なHTMLテーブルには高い。
3. ポイント&クリックのブラウザ拡張
Web ScraperやData Minerのような拡張は、ページ上の要素を視覚的に選択し、クリックで抽出パターンを定義できます。
うまくいくとき:
- 多くの類似ページから同じ種類のデータを抽出する必要がある
- ページのHTML構造が一貫していて予測可能
- ビジュアルセレクターインターフェースの学習に抵抗がない
うまくいかないとき:
- CSSセレクターやHTMLの構造がわからない
- ウェブサイトのレイアウトが頻繁に変わる(セレクターが壊れる)
- 複雑な動的読み込みやshadow DOMを使用するページ
労力: 中(セレクターインターフェースの学習)。 スケール: 中。 正確さ: セレクターが正しければ高い。
4. AI搭載ブラウザ拡張
CSSセレクターを手動で定義する代わりに、AI搭載拡張がページ構造を自動分析してデータフィールドを特定します。
AI Data Extractorはこのアプローチを取ります。拡張をクリックすると、ページ上のテーブル、リスト、構造化コンテンツを自動検出。フィールドを確認して必要に応じて調整し、ワンクリックでCSVまたはJSONにエクスポートします。
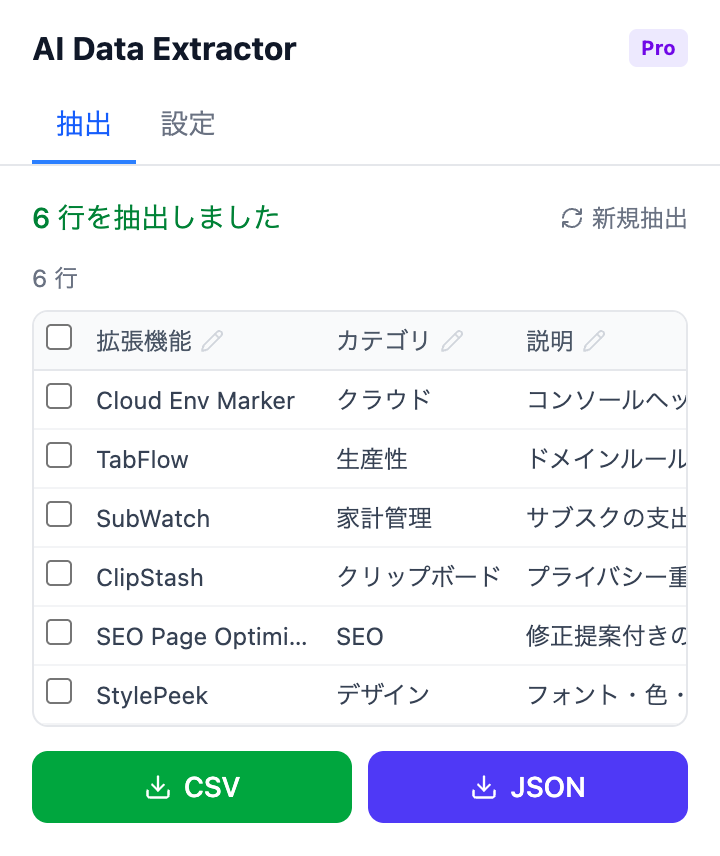
AIが検出したデータフィールド — セレクター設定なしでエクスポート可能
うまくいくとき:
- セレクターを学ばずに構造化データが欲しい
- ページレイアウトが複雑または不規則
- 初めてのページから素早く抽出したい
うまくいかないとき:
- 数千ページを自動的にスケジュール実行で抽出する必要がある
- 非常に特殊または深くネストされたHTML
- 人間のレビューなしで抽出ロジックを実行する必要がある
労力: 非常に低(クリック&エクスポート)。 スケール: 低〜中。 正確さ: 構造化されたページには高い。
5. ノーコードクラウドプラットフォーム(Octoparse、Browse AI、ParseHub)
クラウドベースのプラットフォームは、サーバー上で実行されるスクレイピングワークフローのビジュアルビルダーを提供します。抽出を一度定義すれば、スケジュール実行、ページネーション処理、自動エクスポートまで対応します。
うまくいくとき:
- 同じソースから定期的にデータが必要(日次、週次)
- ページネーションをまたぐ多数のページ
- スプレッドシートやデータベースへの自動配信が欲しい
うまくいかないとき:
- 無料プランのページ制限が厳しい(通常月100〜1,000ページ)
- アンチボット対策がクラウドベースのスクレイパーをブロック
- 月額コスト($30〜$100+)が継続的に発生
労力: 中(ビジュアルビルダー)。 スケール: 高。 正確さ: 適切な設定で高い。
一覧比較
| 方法 | セットアップ | 必要スキル | スケール | 定期実行 | コスト |
|---|---|---|---|---|---|
| コピー&ペースト | なし | なし | 非常に小 | 手動 | 無料 |
| Google Sheets関数 | 2分 | 基本的な関数 | 低〜中 | 自動更新 | 無料 |
| ポイント&クリック拡張 | 15〜30分 | CSSセレクター基礎 | 中 | 半自動 | 無料 |
| AI搭載拡張 | 1分 | なし | 低〜中 | 手動 | 無料 / Pro |
| クラウドプラットフォーム | 30〜60分 | ビジュアルビルダー | 高 | 自動 | 月額$0〜$100+ |
まず何を試すべきか
状況に合った最もシンプルなアプローチから始めましょう:
- 1ページから10行だけ今すぐ必要? コピー&ペースト。完了。
- 自動更新されるテーブルが欲しい? まずGoogle Sheetsの
IMPORTHTMLを試す。 - 一貫したレイアウトの多数のページからデータが必要? ポイント&クリック拡張が手動より時間を節約。
- 構造がわからない初めてのページ? AI拡張がセレクター設定なしで構造を検出。
- 変化するソースから毎週同じデータが必要? クラウドプラットフォームがワークフロー全体を自動化。
多くの人はコピー&ペーストから始め、1ページ以上必要になると壁にぶつかり、いきなり複雑なツールに飛びつきます。その間にある方法 — スプレッドシート関数、ブラウザ拡張、AI検出 — が、実際のニーズの大半が収まる中間地帯をカバーします。
AI抽出を試す: AI Data Extractorは任意のWebページのテーブルと構造化データを自動検出。ワンクリックでCSVやJSONにエクスポート。セレクター不要、コード不要。
この比較記事が役に立ちましたか? Chrome Web Storeでレビューしていただけると、他のユーザーがツールを見つけやすくなります。
ご質問・フィードバックは [email protected] まで。